User manual - Data analyses¶
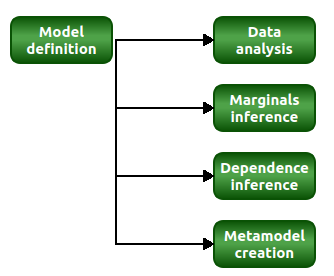
- The interface allows to perform the following types of data analysis:
Data analyses to get moments, minimum, maximum, PDF, etc.
Marginals inferences
Dependence inferences
Metamodels creation
1- Data analysis¶
1-1 Creation¶
- A new sample analysis can be created through:
the context menu of the Definition item of the data model

the Data analysis box of the model diagram
When the analysis is required, a new item is added in the study tree below the data model item.
- Its context menu has the following actions:
Rename: Rename the analysis
Remove: Remove the analysis from the study
This item is associated with a window showing a progress bar and Run/Stop buttons, to launch or stop the analysis.
1-2 Results¶
When the analysis is finished or stopped, the following window appears.
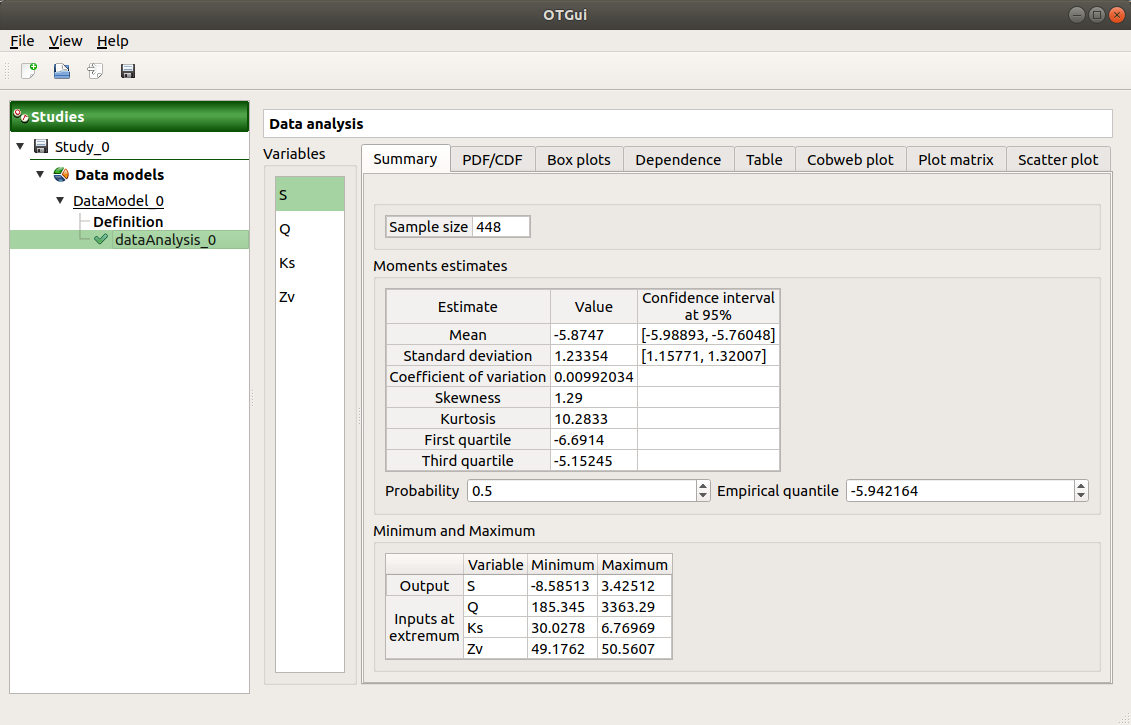
The window shows numerous tabs, some of which are interactively linked (Table, Cobweb plot, Plot matrix and Scatter plot tabs): when the user selects points on one of these representations, the same points are automatically selected in the other tabs.
The Summary tab summarizes the results of the analysis, for a selected variable (left column): sample size, elapsed time, moment estimates, empirical quantiles, minimum/maximum values, input values at extremum.
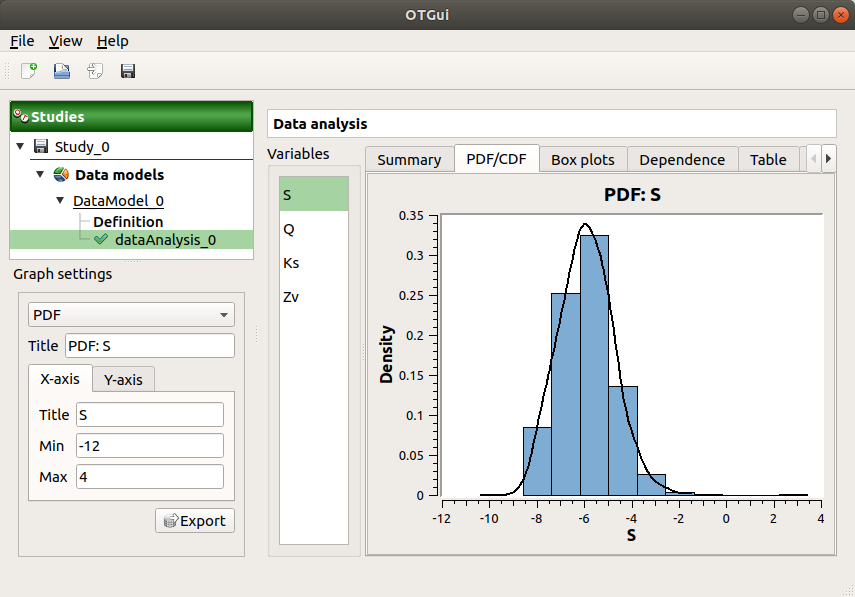
The PDF/CDF tab presents the PDF/CDF of the variables together with a kernel smoothing representation.
Use the Graph settings window to set up graphical parameters and select the graphic type: PDF (default) or CDF
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
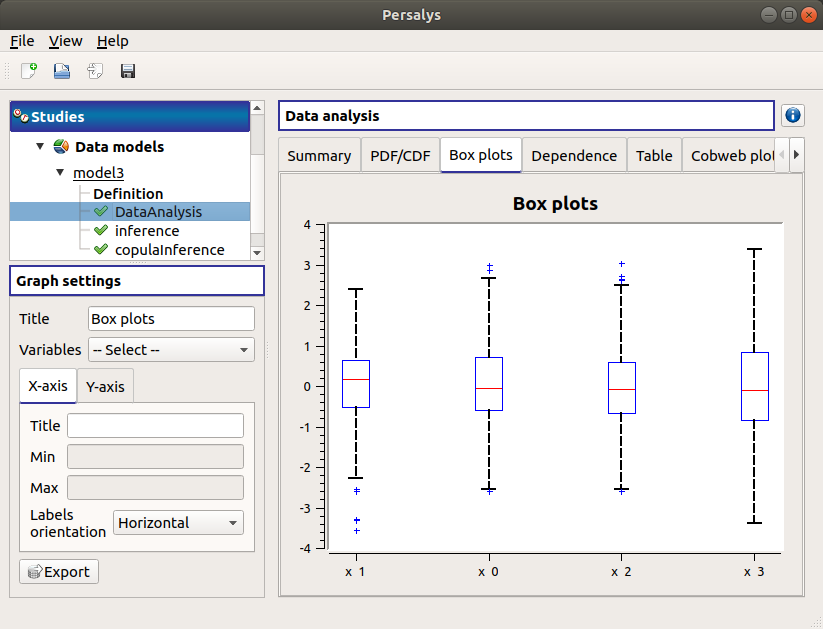
The Box plots tab presents the box plot of the variables. They are rescaled for each variable (
 ), using mean (
), using mean ( ) and standard deviation (
) and standard deviation ( ):
): 
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
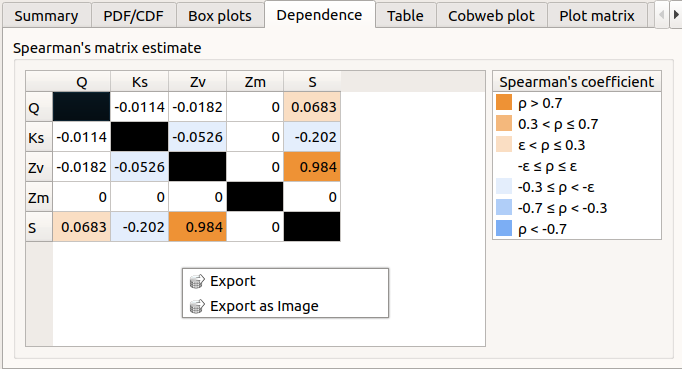
The Dependence tab displays the Spearman’s matrix estimate.
The cells are colored according to the value of the Spearman’s coefficient.
Its context menu allows to export the table in a CSV file or as a PNG image.
Select cells and Press Ctrl+C to copy values in the clipboard
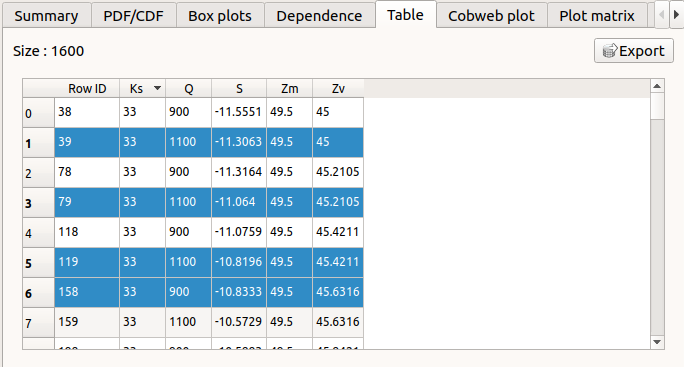
The Table tab shows the input/output samples. The table can be exported (Export button).
- Table interactivity:
Left-click (optional: + Ctrl) on lines to select them
Left-click on column header to sort values in ascending or descending order
Left-click on a column header and drag it in another place to change columns order
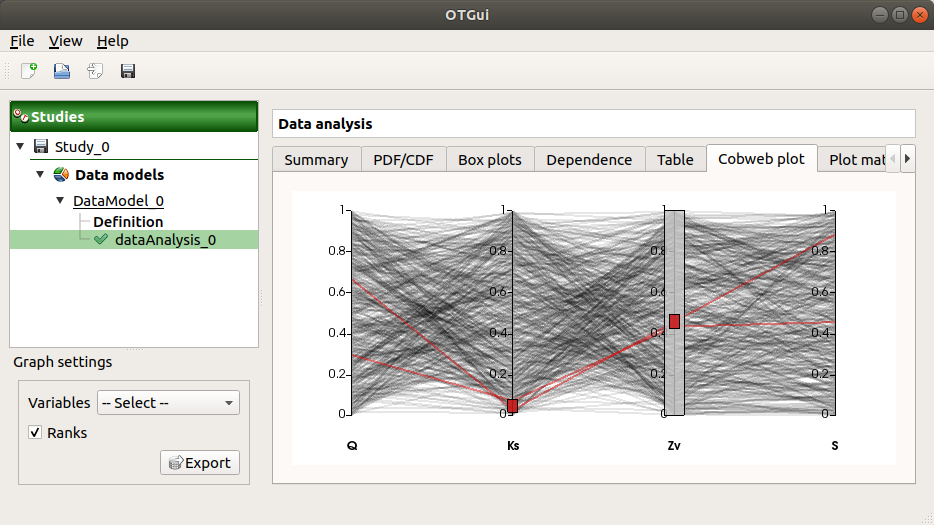
The Cobweb plot tab displays the sample points.
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Left-click on columns to select curves (multiple selection possible)
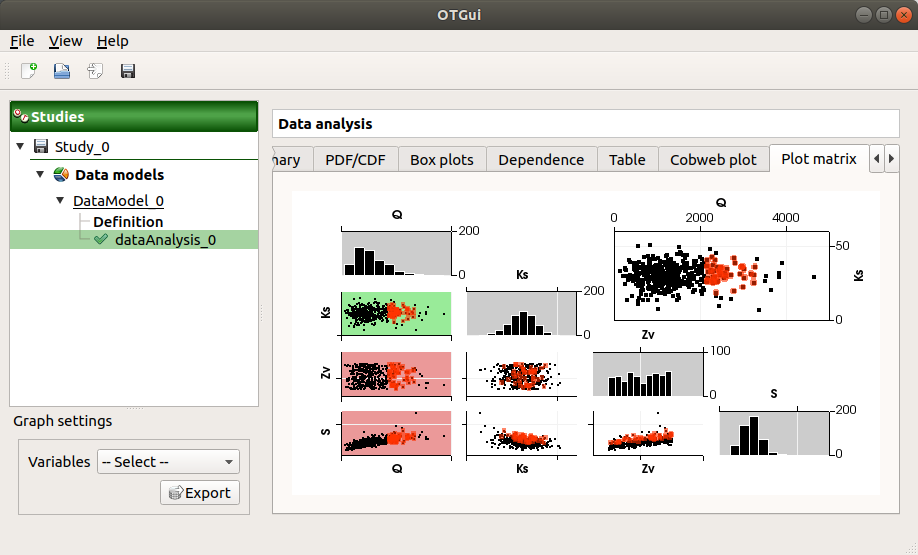
The Plot matrix tab: histograms of the distribution of each variable (diagonal) and scatter plots between each couple of input/output variables (off-diagonal).
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Right-click to select points
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
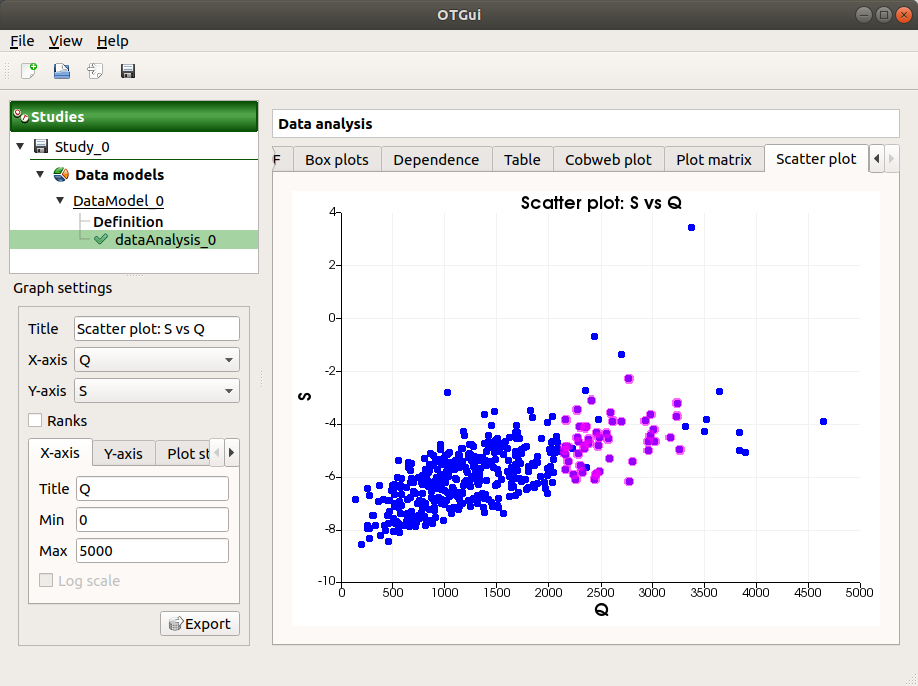
The Scatter plots tab displays the scatter plot of two parameters.
Use the Graph settings window to set up graphical parameters and select the variables to plot on X-axis and Y-axis (default: first output versus first input)
- Graph interactivity:
Right-click to select points
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
2- Marginals inference¶
The inference analysis allows to perform a Bayesian Information Criterion (BIC) and a Kolmogorov-Smirnov goodness-of-fit tests for 1-d continuous distributions.
- New marginals inference can be created thanks to:
the context menu of the Definition item of the data model
the Marginals inference box of the model diagram
2-1 Definition¶
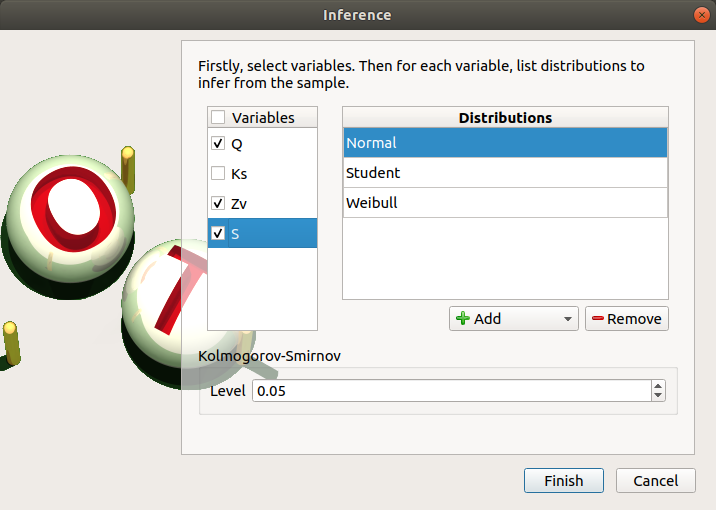
- When an analysis is required, a window appears, in order to set up:
the variables of interest (default: all variables are analysed) by checking off the corresponding line in the first table
- the list of distributions to infer for each variable (default: Normal distribution):
The list of distributions can be different for each variable.
Click on Apply the list of distributions to all variables in the context menu of a variable to set up the same list of distributions to the other checked variables.
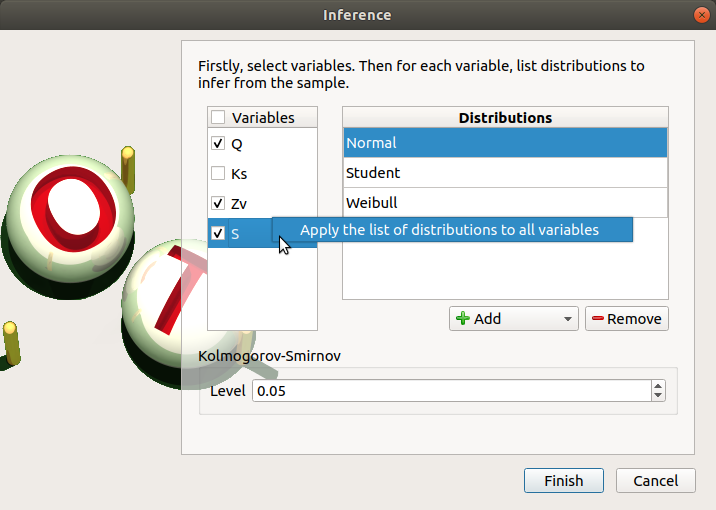
To add a distribution, click on the Add combo box and select a distribution of the list which appears (or all of them with the All item):
the distribution is added in the table
the distribution is removed from the combo box
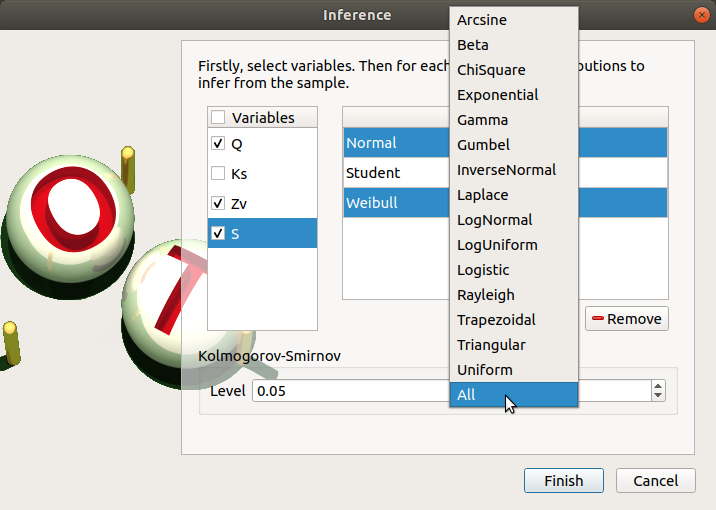
To remove a distribution, select it in the table and click on Remove. Press the Ctrl or Shift key to select multiple lines.
the Kolmogorov-Smirnov level such that
 is the risk of
committing a Type I error, that is an incorrect rejection of a true null hypothesis
(default: 0.05., expected: float in the range
is the risk of
committing a Type I error, that is an incorrect rejection of a true null hypothesis
(default: 0.05., expected: float in the range ![]0, 1[](../../../_images/math/8db71e078761684e86d28c847485b4a900427230.svg) )
)
2-2 Launch¶
When the analysis is required, a new item is added in the study tree below the data model item.
- Its context menu has two actions:
Rename: Rename the analysis
Modify: Reopen the setting window to change the analysis parameters
Remove: Remove the analysis from the study
This item is associated with a window displaying the list of the parameters, a progress bar and Run/Stop buttons, to launch or stop the analysis.
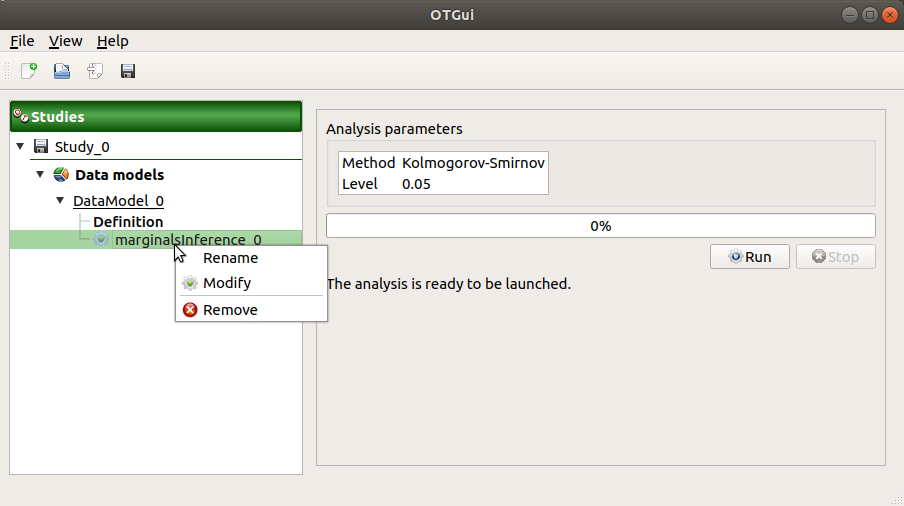
2-3 Results¶
When the analysis is finished or stopped, a window appears.
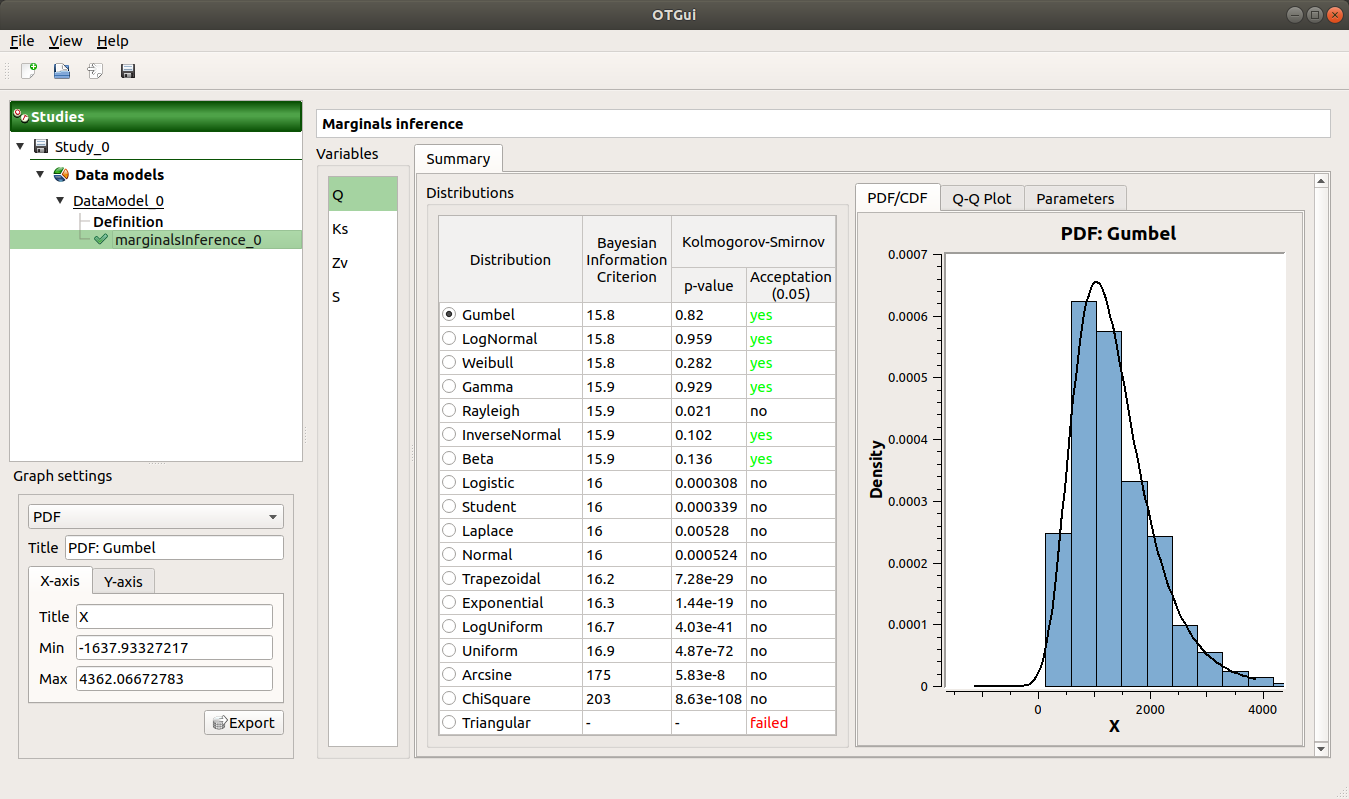
The results window gathers:
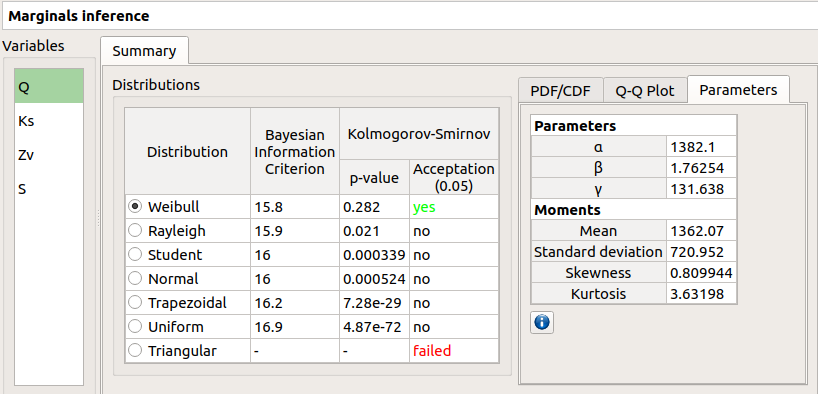
- The Summary tab includes, for a selected variable (left column):
- a table of all the tested distributions, the associated Bayesian Information Criterion value and the p-value.
The last column indicates whether the distribution is accepted or not according to the given level.
The distributions are sorted in increasing order of BIC values.
- for the selected distribution:
The PDF/CDF tab presents the PDF/CDF of the sample together with the distribution PDF.
Use the Graph settings window to set up graphical parameters and select the graphic type: PDF (default) or CDF
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
The Q-Q plot tab presents the Q-Q plot which opposes the data quantiles to the quantiles of the tested distribution.
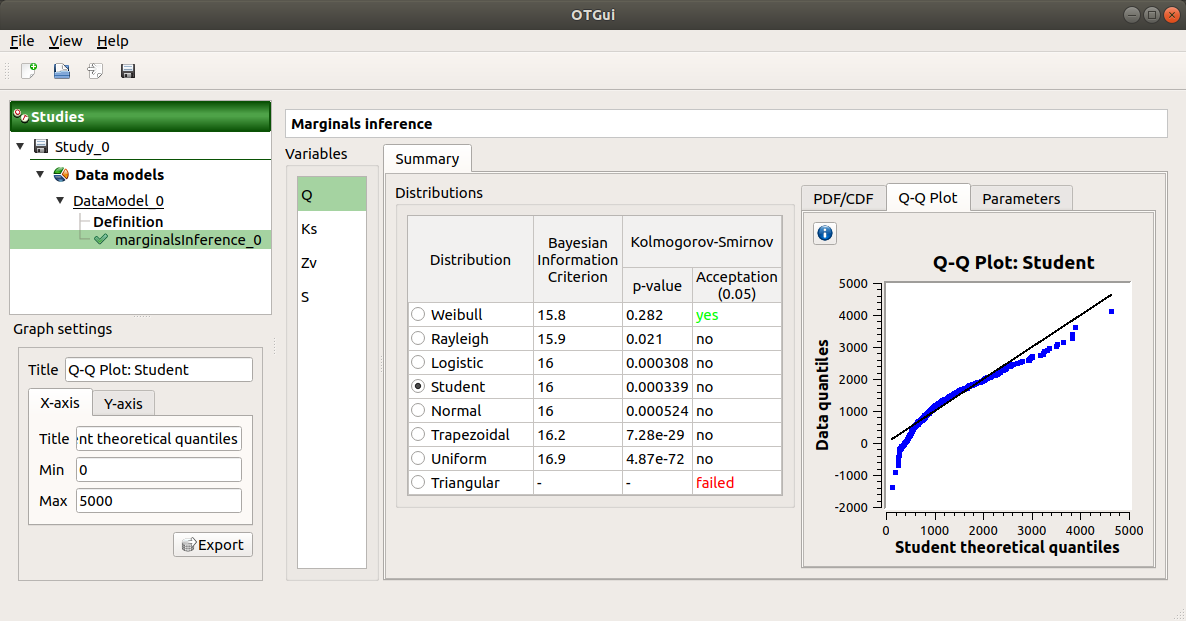
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
The Parameters tab includes a table with the moments of the selected distribution and the values estimate of its native parameters.
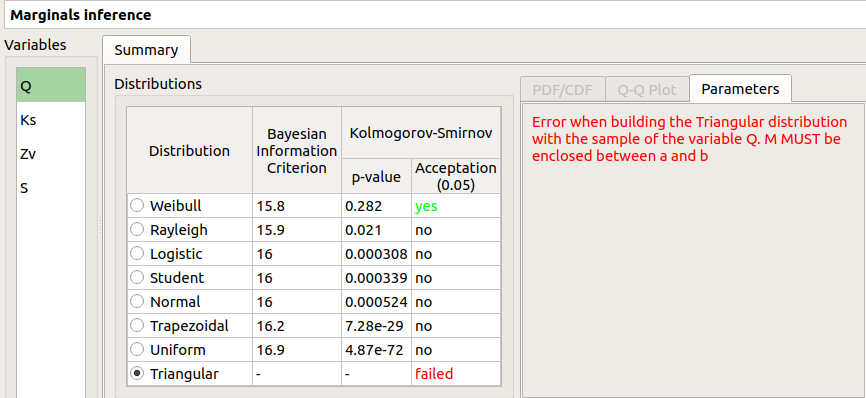
failed in the Acceptation column means that an error occured when building a distribution with the given sample. Then, the Parameters tab shows the error message.
The result can be used in the Probabilistic model window.
3- Dependence inference¶
The dependence inference allows to infer copulas on the sample of the data model.
- This analysis can be created thanks to:
the context menu of the Definition item of the relevant data model
the Dependence inference box of the model diagram
3-1 Definition¶
When an analysis is required, a window appears:
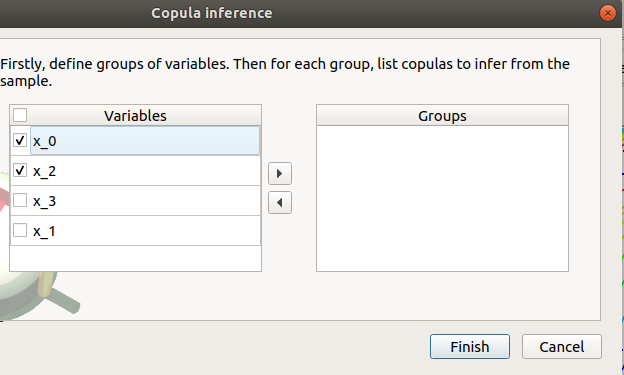
- The windows allows to set up:
- the groups of variables to test:
- Select at least two variables of the model (left table):
Refer to the estimate of the Spearman’s matrix in the data analysis result window to create groups
For convenience, the list of groups may be set by default thanks to this estimate (if correlation between variables exists)
- Click on the right arrow:
the group is added in the second table
a third table appears with the default item Normal
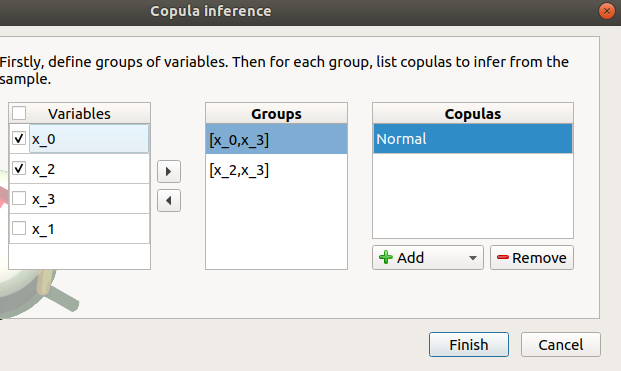
the copulas to infer on the groups: - Click on the Add combo box - Select a copula in the list (or all of them with the All item):
For a pair of variables : bivariate copulas are available (Ali-Mikhail-Haq, Clayton, Farlie-Gumbel-Morgenstern, Frank, Gumbel, Normal)
For a group with more than two variables: only the Normal copula is available (Add and Remove buttons are then disabled)
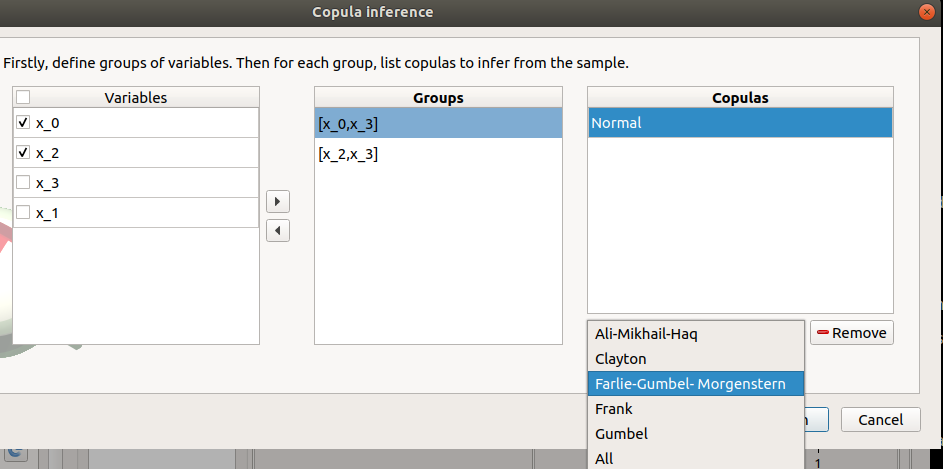
- To remove a group:
Select a group in the second table
Click on the left arrow
3-2 Launch¶
When the analysis is required, a new item is added in the study tree below the data model item.
- Its context menu has the following actions:
Rename: Rename the analysis;
Modify: Reopen the setting window to change the analysis parameters;
Remove: Remove the analysis from the study.
This item is associated with a window displaying the list of the parameters, a progress bar and Run/Stop buttons, to launch or stop the analysis.
3-3 Results¶
When the analysis is finished or stopped, a window appears:
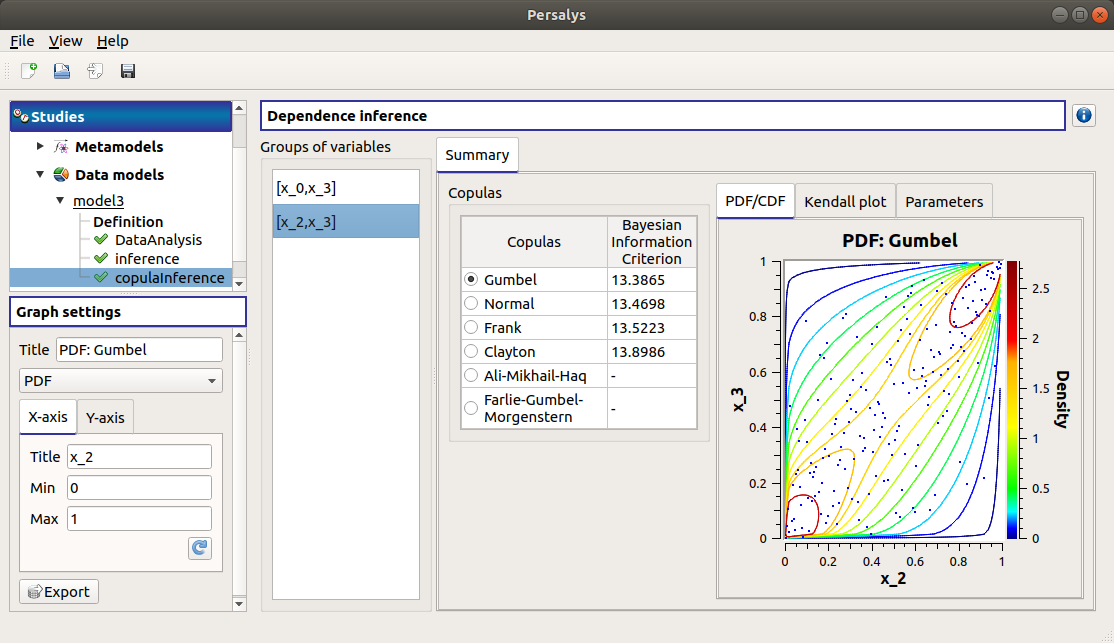
The window gathers:
- The Summary tab includes, for a selected set of variables:
a table of all the tested copulas
- for the selected copula:
the PDF/CDF tab presents, for each pair of variables, the PDF/CDF of the sample together with the distribution PDF.
Use the Graph settings window to set up graphical parameters and select the graphic type: PDF (default) or CDF
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
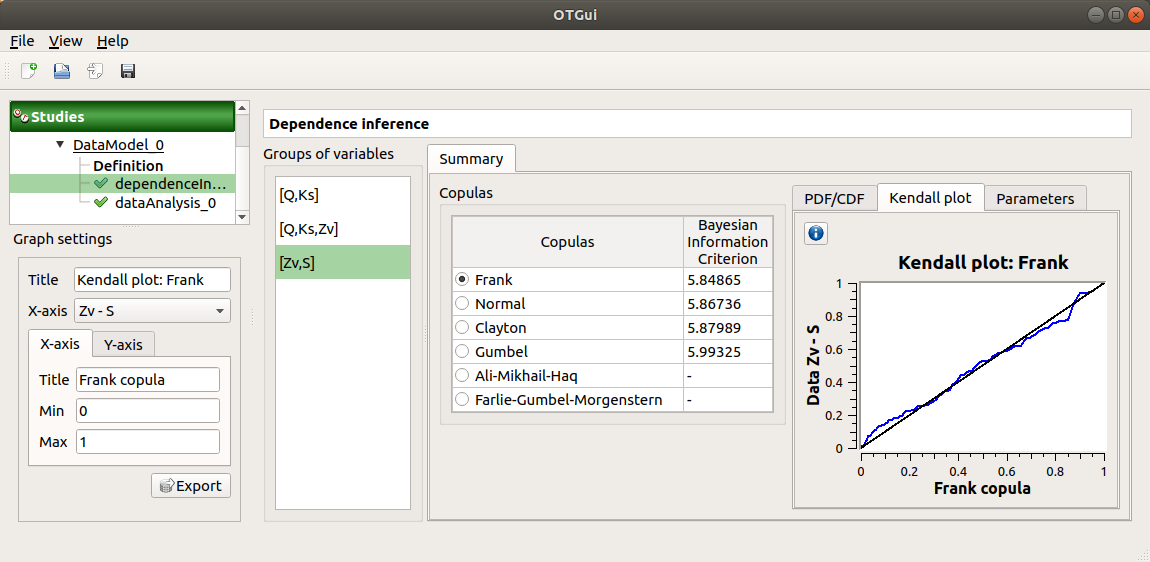
the Kendall plot tab presents a visual fitting test for each pair of variables using the Kendall plot. This plot can be interpreted as a QQ-plot (for marginals): the more the curve fits the diagonal, the more adequate the dependence model is.
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
the Parameters tab includes the parameters estimate of the selected copula.
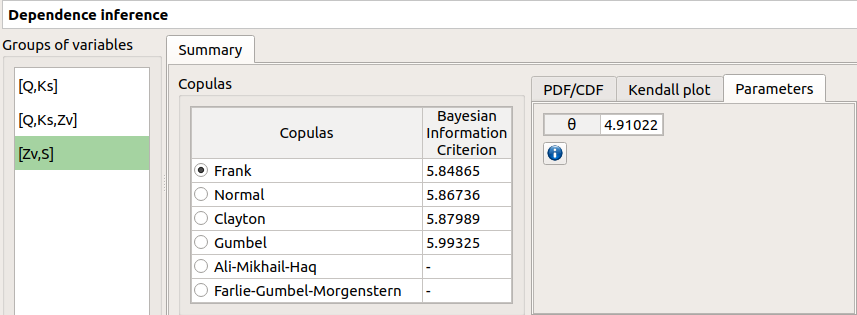
For the Gaussian copula: the tab displays the Spearman’s coefficients.
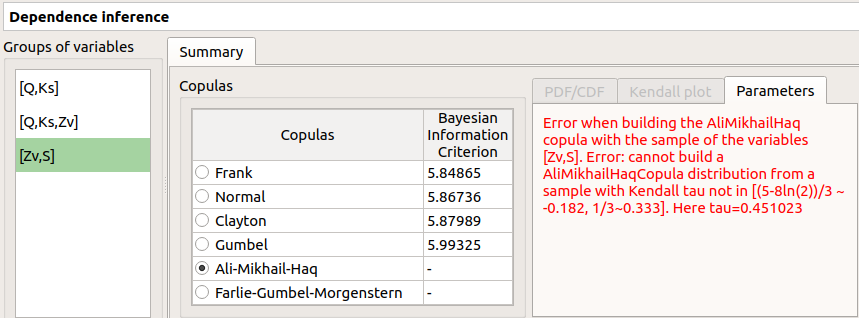
‘-‘ in the BIC column means that an error occured when building a copula with the given sample. Then, the Parameters tab shows the error message.
The result can be used in the Probabilistic model window.
4- Metamodel creation¶
To perform this analysis, the data model or the design of experiments must contain an output sample.
- A new metamodel can be created in 4 different ways:
the context menu of a design of experiments item
the Metamodel creation box of a physical model diagram

the context menu of the Definition item of a data model
the Metamodel creation box of a data model diagram
4-1 Definition¶
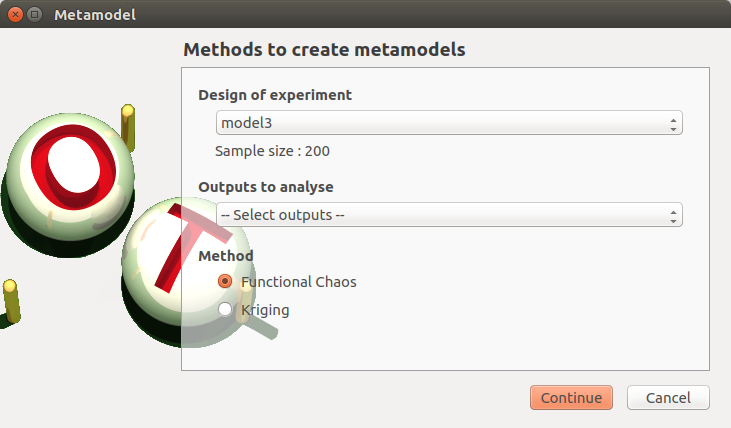
- When an analysis is required, a window appears, in order to set up:
the outputs of interest (Select outputs - default: all outputs are analyzed)
the method: Functional chaos (default) or Kriging
4-1-1 Functional chaos¶
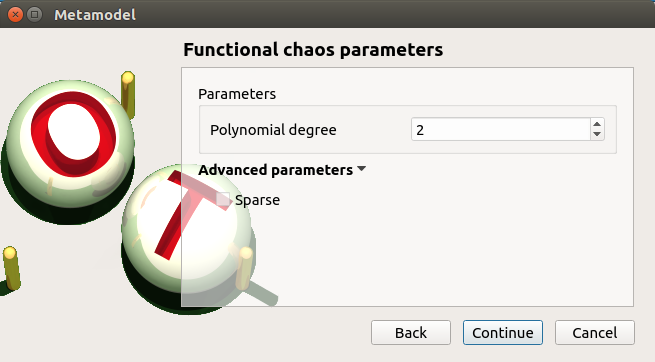
- The Functional chaos parameters window allows to define:
Parameters: chaos degree (default: 2, expected: integer greater or equal to 1)
Advanced Parameters (default: hidden): sparse chaos (default: not sparse)
4-1-2 Kriging¶
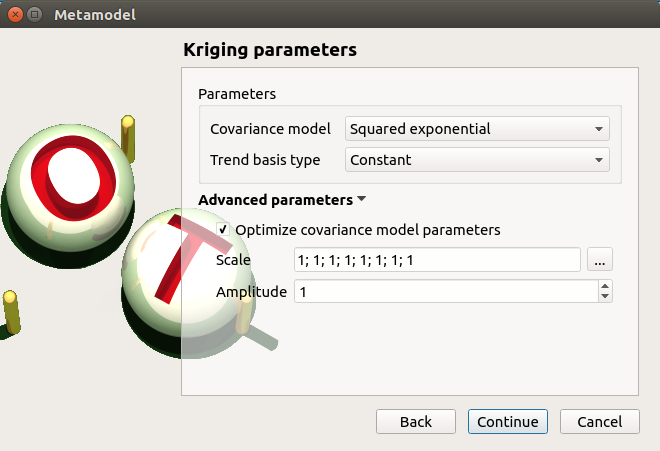
- The Kriging parameters window allows to define:
- Parameters:
The type of covariance model: Squared exponential (default), Absolute exponential, Generalized exponential, Matérn model
- Parameters of the covariance model (default: hidden, visible if a model is choosen):
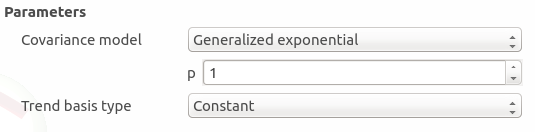
Generalized exponential: parameter p, exponent of the euclidean norm (default: 1., positive float expected)
Matérn: coefficient nu (default: 1.5, positive float expected)
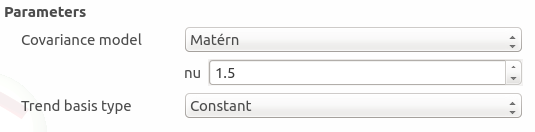
The type of the trend basis: Constant (default), Linear or Quadratic
- Advanced Parameters are accessible for model covariance optimization (default: hidden):
Optimize the covariance model parameters (default: checked)
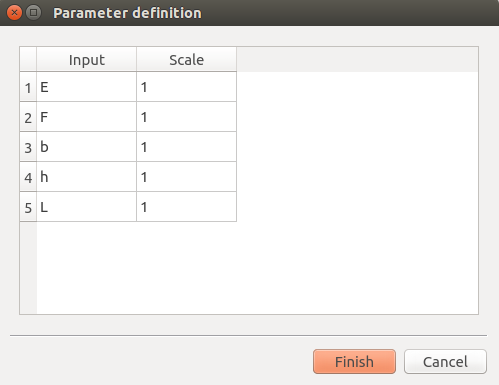
Scales for each input (default: 1): To edit the scales, click on the “…” button to generate the input variables table and their scale through a wizard.
Amplitude of the process (default: 1., positive float expected)
4-1-3 Validation¶
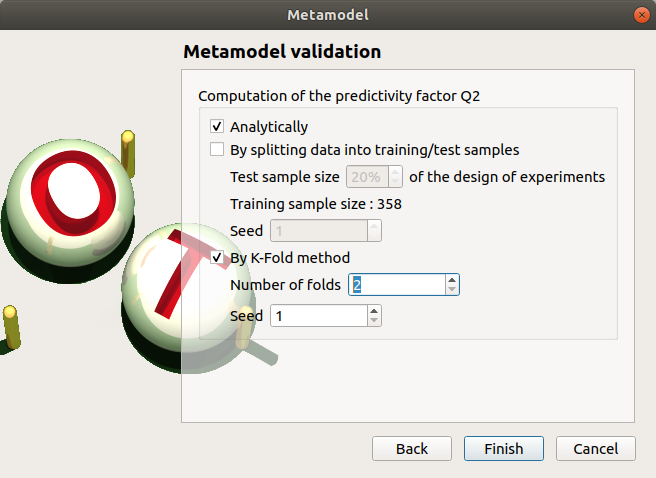
- In the following window, the generated metamodel can be validated, with three different methods:
- Analytically (default): This method corresponds to an approximation of the Leave-one-out method result.
For more information about Kriging, see O. Dubrule, Cross Validation of Kriging in a Unique Neighborhood, Mathematical Geology,1983.
For more information about Functional chaos, see G. Blatman, Adaptive sparse polynomial chaos expansions for uncertainty propagation and sensitivity analysis., PhD thesis. Blaise Pascal University-Clermont II, France, 2009.
Using a test sample: The data sample is divided into two subsamples, by picking points randomly (default seed = 1): training sample (default: 80% of the sample points) and test sample (default: 20% of the sample points). A new metamodel is built with the training sample and is validated with the test sample.
Using the K-Fold method: Define the number of folds (default: 5, expected: integer greater than 1) and specify how the folds are generated (default seed:1).
4-2 Results¶
When the window is validated, a new element appears in the study tree below the data model item or the design of experiments item.
- The context menu of this item contains these actions:
Rename: Rename the analysis
Modify: Reopen the setting window to change the analysis parameters
Convert metamodel into physical model (default: disabled, enabled when the analysis is successfully finished): Add the metamodel in the study tree
Remove: Remove the analysis from the study
This item is associated with a window displaying the list of the parameters, a progress bar and Run/Stop buttons, to launch or stop the analysis.
4-2-1 Functional chaos¶
The results window gathers:
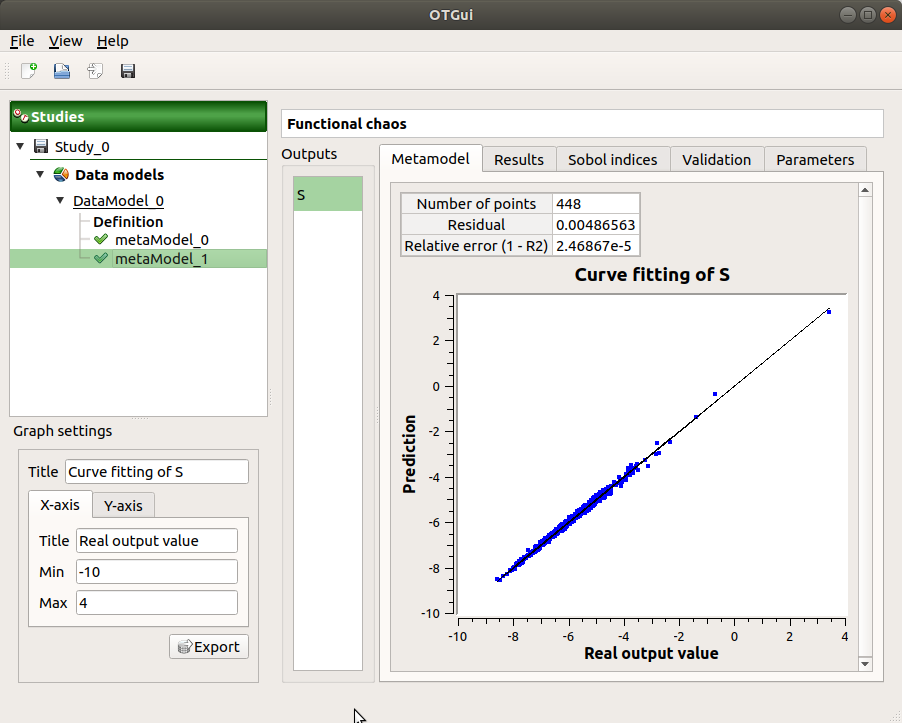
- The Metamodel tab shows different information about the selected output (left column):
Number of points
Relative error:

Residual:
 .
.The fitting curve between the physical model output values (Real otput values) and the metamodel values (Prediction). The reference diagonal (in black) is built with the physical model output values.
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
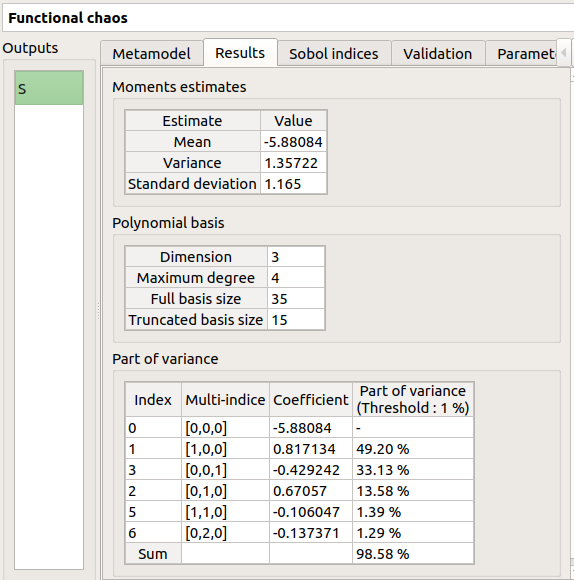
- The Results tab presents different parameter, for a selected output (left column):
first and second order moments
polynomial basis: dimension, maximum degree, full/truncated size
part of variance explained by each polynom
The Sobol indices tab includes, for a selected output (left column):
The graphic representation of the first and total order indices for each variable. Use the Graph settings window to set up graphical parameters.
A summary table with the first and total order indices.
- Table interactivity:
Select cells and Press Ctrl+C to copy values in the clipboard
Left-click on column header to sort values in ascending or descending order. Sorting the table will automatically sort the indices on the graph.
The index corresponding to the interactions (below the table).
If the Sobol’s indices estimates are incoherent, an
 will appear in the table.
It is advised to refer to the associated warning message (tooltip of the ).
will appear in the table.
It is advised to refer to the associated warning message (tooltip of the ).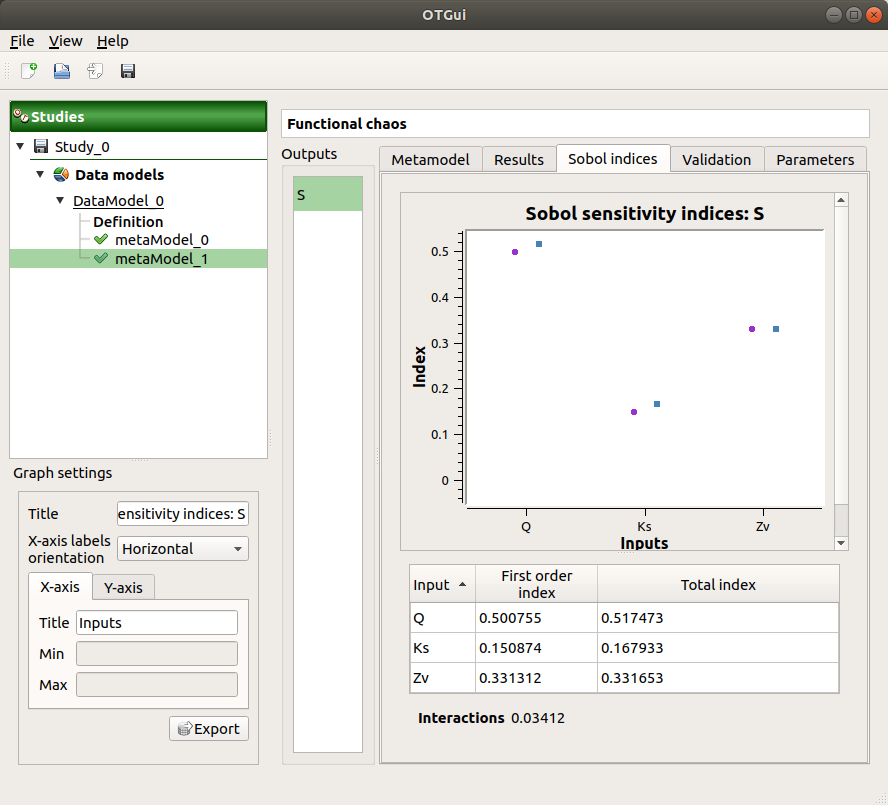
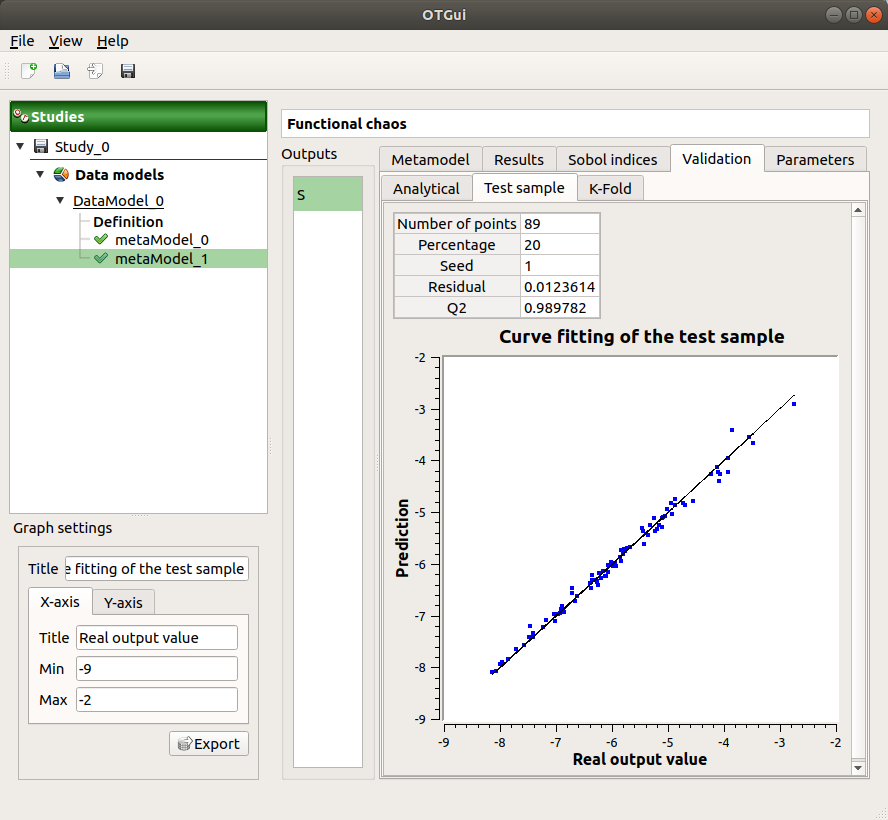
- The Validation tab (default: hidden; visible if a metamodel validation is required) shows for each method and selected output:
The metamodel predictivity coefficient:

The residual:
.K-Fold and Test sample: A plot showing the relation between the output values (physical model) and the predicted metamodel values. The relation is compared to a reference diagonal built with the physical model output values.
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
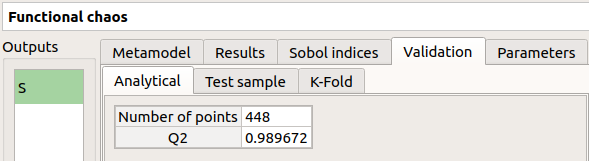
Analytical: the Q2 value
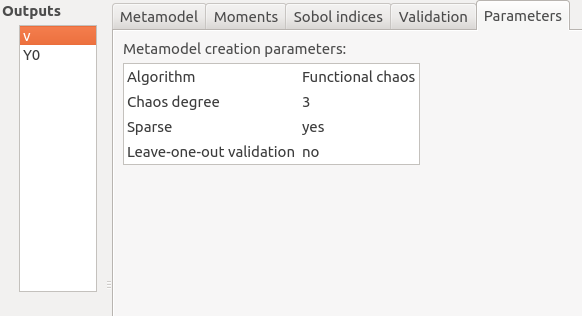
The Parameters tab summarizes the parameters of the metamodel creation.
4-2-2 Kriging¶
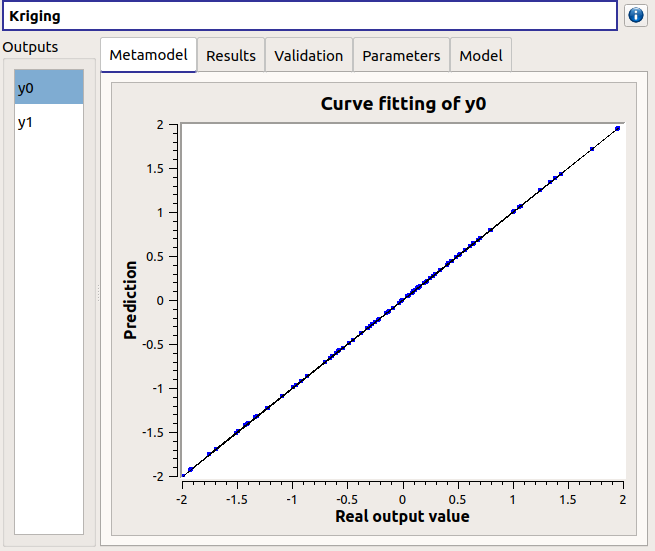
The results window gathers:
The Metamodel tab shows for a selected output the graphic relation between output values from the physical model (Real output values) and metamodel values (Prediction). The reference diagonal (in black) is built with the physical model output values.
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
The Results tab presents the optimized covariance model parameters and the trend coefficients.
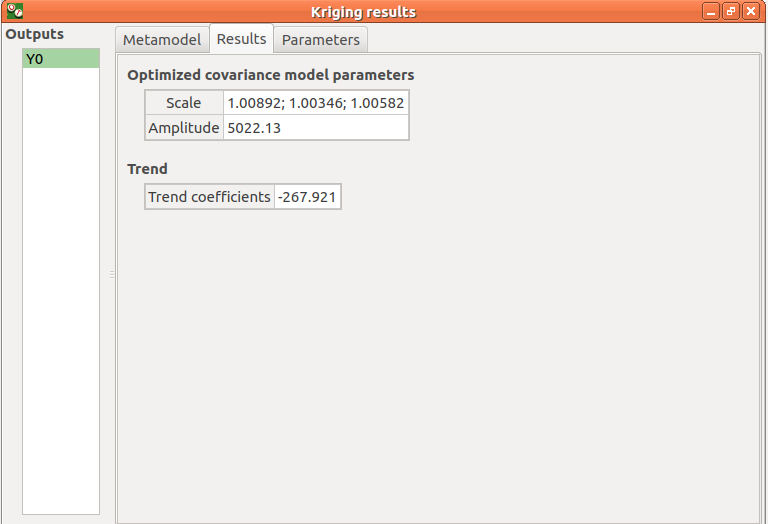
- If a metamodel validation is required, a Validation tab appears for the selected method and output:
The residual:
.The metamodel predictivity coefficient:
A plot showing the relation between the output values (physical model) and the predicted metamodel values. The relation is compared to a reference diagonal built with the physical model output values.
Use the Graph settings window to set up graphical parameters.
- Graph interactivity:
Left-click to translate the graph
Mouse wheel up/down to zoom in/zoom out
The Parameters tab summarizes the parameters of the metamodel creation.